 1. Å definere en første tjenlig mutasjon
1. Å definere en første tjenlig mutasjon
Bilde 1: Hva er mulig ved naturlige årsaker?
Første problem vi står overfor i forbindelse med tjenlige punkt-mutasjoner, er å definere hva vi mener med tjenlig. Ingen av de fire nukleotidene (A,T,C eller G) er i seg selv mer tjenlig eller ønskelig enn de andre. Så tjenlige mutasjoner kan bare forekomme i konteksten av omkringliggende nukleotider. Akkurat som tjenligheten av en endring av en enkelt bokstav i en tekst, bare kan vurderes i forhold til omkringliggende tekst. Vi kommer imidlertid opp i et paradoks: De samme omgivelsene som kan tjene til å velge ut en fordelaktig mutasjon, vil måtte endres for at mutasjonen skal bli tjenlig. Problemet med fundamental inter-avhengighet og samvirke mellom nukleotider, kalles epistase (komplementær genvirkning). Genomet er bokstavelig en form for 'bok'. Vi kan la 3 nukleotider -i ett kodon, tilsvare en bokstav. Da har en 1 milliard bokstaver, skrevet i et språk med korte sekvenser (setninger). At en slik funksjonell streng av nukleotider skal 'falle på plass ved tilfeldigheter', er ikke mulig statistisk sett. For å ha en nedre grense på hva som er mulig av naturlige
grunner, tar vi med en figur til høyre, med W.Dembskis mål for dette.
 2. Mutasjon blant mennesker –historikk
2. Mutasjon blant mennesker –historikk
Bilde 2: Eks. på punkt-mutasjon
Menneskelig evolusjon antas vanligvis å ha inntruffet i en liten populasjon på omkring 10.000 individer. Mutasjons-andel for hver nukleotide pr. person pr. generasjon er ytterst beskjeden. Om vi antar 100 mutasjoner pr. person pr. generasjon (én sjanse på 30 millioner). Da måtte vi vente 3000 generasjoner (minst 60.000 år) mens vi ventet på at én nukleotide muterte.
(Beregning: Mutasjonsfrekvens i #generasjoner: #nukleotider pr. genom/(#mutasjoner pr. person*#personer ) pr. gen.sjon= 3milliarder/(100*10.000) =3.000 generasjoner eller minst 60.000 år.)
I ett kodon med 3 nukleotider, vil mutasjonen 2 av 3 ganger forekomme i feil nukleotide. Som ett gjennomsnitt kan vi regne 2 generasjoner for at ‘rett nukleotide’ treffes. Det vil innebære en dobling til 120.000 år. Når mutasjonen har inntruffet, må den bli fiksert-slik at alle individer i populasjonen har 2 kopier av den. Fordi nye mutasjoner er så sjeldne, har de en ekstremt høy sannsynlighet for å gå tapt, som følge av tilfeldig genetisk drift. Bare om mutasjonen er dominant og har en meget distinkt fordel, har seleksjon en rimelig sjanse til å redde den fra tilfeldig eliminasjon via genetisk drift. I forhold til antall ikke-muterte nukleotider i populasjonen er sannsynligheten for ikke å gå tapt i størrelsesorden 1: 10.000. Spesielt gjelder dette når en vet at så godt som samtlige mutasjoner er recessive og nesten nøytrale. F.eks. har en mutasjon med en svak økning i fitness (0,5%), en sjanse på 1% for å bli fiksert i populasjonen. I snitt vil den altså gå tapt 99 av 100 ganger. I snitt må vi altså vente 100*120.000 = 12 millioner år for å stabilisere den første tjenlige mutasjon. Det er dobbelt så lang tid som tiden fossiler det er mellom apelignende forfedre og mennesket (homo erectus) oppsto. Da er det behov for anslagsvis 40 millioner mutasjoner..
3. I påvente av andre mutasjoner
Prosessen med å stabilisere (fiskere) 1.mutasjon i trengs å repeteres for alle andre nukleotider, som koder for vårt hypotetisk håpefulle gen. Et gen er minimum 1.000 nukleotider langt. (Da ser en bort fra alle regulerende element og alle introner). Så om denne prosessen er en lineær og sekvensiell prosess, skulle det ta 1.000 ganger så lang tid, omkring 12 milliarder år (litt yngre enn universet). Så det er mer enn sørlandsk underdrivelse å si at 'sjeldenheten ved tjenlige mutasjoner begrenser evolusjonsraten'..
Prosessen med å stabilisere (fiskere) 1.mutasjon i trengs å repeteres for alle andre nukleotider, som koder for vårt hypotetisk håpefulle gen. Et gen er minimum 1.000 nukleotider langt. (Da ser en bort fra alle regulerende element og alle introner). Så om denne prosessen er en lineær og sekvensiell prosess, skulle det ta 1.000 ganger så lang tid, omkring 12 milliarder år (litt yngre enn universet). Så det er mer enn sørlandsk underdrivelse å si at 'sjeldenheten ved tjenlige mutasjoner begrenser evolusjonsraten'..
4. Mens vi venter på rekombinasjoner (Godot)..
Fordi arter med kjønnet formering kan ‘skyfle over’ (shuffle) mutasjoner, kan noen tro at alle nødvendige mutasjoner for ett gen, kan opptre samtidig i ulike individer, og at så alle de ønskelige mutasjoner kunne ‘spleises sammen’ via rekombinasjoner. ‘Simultan overføring av mutasjoner, i stedet for sekvensiell’. Dermed ville en trenge mindre enn milliarder av år. Det er minst 2 problemer med dette:
1. Når vi undersøker det menneskelige genom, ser en at det er satt sammen av store blokker (på 20.000-40.000 nukleotider). Internt i disse har ikke rekombinasjoner funnet sted siden menneskets opprinnelse. Det er kun store gen-blokker som blir forflyttet (shuffled). Det foregår ikke nukleotide-skyfling på individuelt nukleotide nivå.
2. Selv om det –på ett eller annet vis, skulle forekomme, ville muligheten for at samtlige 1000 mutanter skulle skyfles over samtidig, være astronomisk liten. Om det på hypotetisk vis skulle skje, ville denne samme ekstensiv mutasjons-skyflingen ødelegge det den bygde opp, etter 1 generasjon. For å ta et bilde: om en har fått tildelt ‘royal flush’ i poker, hva er så muligheten for å få det på ny, etter at kortene er refordelt?
5. Mens vi venter på Haldane’s dilemma
Bilde 3: For liten tid?
 Når først én mutasjon er blitt stabil (fixed) innen populasjonen, trengs tid for å gjennomgå selektiv utvidelse. En helt ny mutasjon innen en populasjon på 10.000 mennesker eksisterer bare som en nukleotide blant 20.000 andre i samme posisjon innen populasjonen. Den mutante nukleotiden må gradvis ‘vokse’ innen befolkningen, enten grunnet genetisk drift eller naturlig seleksjon. Snart kan det bli 2, så 4, så 100 og til slutt 20.000. Tiden det tar, vil avhenge av om mutasjonen er dominant. Om det er sterk, ikke-styrt seleksjon, så kan mutasjonen vokse innen populasjonen, med en rate på 10% per generasjon. Selv med denne raske takten, ville det ta 105 generasjoner (2.100 år) å øke fra 1 til 20.000 kopier ( ). Men hovedregelen er at mutasjoner er recessive og seleksjon veldig svak, dermed tar det vanligvis mye lenger tid. Selv om en recessiv mutasjon førte til en økning i fitness på 1% pr. generasjon, trengs minst 100.000 generasjoner å stabilisere den (Patterson, 1999)
Når først én mutasjon er blitt stabil (fixed) innen populasjonen, trengs tid for å gjennomgå selektiv utvidelse. En helt ny mutasjon innen en populasjon på 10.000 mennesker eksisterer bare som en nukleotide blant 20.000 andre i samme posisjon innen populasjonen. Den mutante nukleotiden må gradvis ‘vokse’ innen befolkningen, enten grunnet genetisk drift eller naturlig seleksjon. Snart kan det bli 2, så 4, så 100 og til slutt 20.000. Tiden det tar, vil avhenge av om mutasjonen er dominant. Om det er sterk, ikke-styrt seleksjon, så kan mutasjonen vokse innen populasjonen, med en rate på 10% per generasjon. Selv med denne raske takten, ville det ta 105 generasjoner (2.100 år) å øke fra 1 til 20.000 kopier ( ). Men hovedregelen er at mutasjoner er recessive og seleksjon veldig svak, dermed tar det vanligvis mye lenger tid. Selv om en recessiv mutasjon førte til en økning i fitness på 1% pr. generasjon, trengs minst 100.000 generasjoner å stabilisere den (Patterson, 1999)
Haldane (1957) kalkulerte at det i gjennomsnitt ville ta 300 generasjoner (> 6000 år) å stabilisere en mutasjon, gitt en standard mixture av recessive og dominante mutasjoner. Seleksjon i en slik sammenheng er så sen, at det nesten er som det ikke forekommer. Dette problemet er tradisjonelt kalt ‘Haldanes dilemma’. Under slike omstendigheter kan en bare stabilisere (fiksere) 1.000 tjenlige nukleotide-mutasjoner i genomet på den tiden det skulle tatt å utvikle oss fra en apelignende stamfar (6 millioner år). Dette er uavhengig bekreftet av Crow og Kimura (1970) og ReMine (1993 og 2005) . Naturen ved seleksjon er slik at å selektere for én nukleotide, reduserer evnen til å selektere for andre (seleksjons interferens). Det er likevel verdt å merke seg at Haldanes kalkulasjoner bare gjaldt uavhengige, ikke-linkede mutasjoner. Å selektere for 1000 tilgrensende/nærliggende mutasjoner, kunne ikke skje. Grunnen er at en ikke kan selektere for mutasjoner som ikke skjer. Dessuten med de aller fleste nukleotid-mutasjoner nær nøytrale, og kan ikke selekteres for (Kimuras ‘no-selection box’). Dette begrenser hardt progressiv seleksjon. Et maksimum på 1000 ikke-linkede tjenlige mutasjoner, tilsvarer mindre informasjon enn det er i ett avsnitt for denne tekstsiden. (Regner at ett kodon (tre nukleotider) røft tilsvarer én typografisk bokstav, og at 1000 nukleotider tilsvarer ca. 333 tegn.)

Bilde 3 Stadig degenerering
I denne sammenheng må det trekkes inn en sammenlikning til det som det handler om. Siden mennesker og aper ‘skilte lag’ , tror genetikere at mange tusen av skadelige mutasjoner skal ha blitt rettet opp via genetisk drift. (Kondrashov, 1995; Crow, 1997; Eyre-Walker og Keightley, 1999; Higgins og Lynch, 2001) Evolusjonære formodninger skulle lede til den logisk konklusjon at vi signifikant er degenerert fra våre ape-like forfedre. I våre dager vet vi at sjimpanser og mennesker atskiller seg på omtrent 150 millioner nukleotide posisjoner (Brittan, 2002). Dette grunnes i minst 40 millioner hypotetiske mutasjoner . I løpet av menneskets historie må det ha skjedd minst 20 millioner nukleotide stabiliseringer (fixations). Men naturlig seleksjon kunne altså bare ha sørget for ca. 1000 av disse. Alle de øvrige måtte ha blitt fiksert ved tilfeldig drift. Følgen ville være millioner av nær-nøytrale, skadelige mutasjoner. Det ville ikke bare gjøre oss mindreverdige i forhold til apene, men det ville være direkte dødelig!
6. Endeløse daler av ‘fitness’
Evolusjonister regner med at dannelsen av ett nytt gen medfører en god del eksperimentering. Gjennom konstruksjonsfasen med å utvikle et nytt gen, må vi forvente en periode der eksperimentet reduserer artens fitness. Det er hva som ligger i uttrykket ‘fitness dal’. Et halvt-fullført gen er verken tjenlig eller nøytralt. Det kommer til å bli skadelig. På en måte må arten bli verre, før den kan bli bedre. Det er lett å forestille seg en art som overlever ‘fitness-daler’ om de er korte og sjeldne. Dype ‘fitness-daler’ derimot vil sannsynlig føre til at arten dør ut. Sjeldenheten til tjenlige mutasjoner i kombinasjon med Haldanes dilemma, skulle gjøre ‘fitness-daler’ ubestemt lange og dype. Vedvarende evolusjonær innovasjon ville føre til at en arts fitness avtar uten ende. Evolusjonens motorvei ville alltid være under konstruksjon, og total fitness vil alltid avta framfor å øke. Om hele genomet betraktes, så taler forestillingen om ‘fitness-daler’ i mot evolusjons-scenariet.
7. Flersidig-begrenset (poly-constrained) DNA
De fleste DNA-sekvenser er flerfunksjonelle, og må sådan være flersidig begrenset. At de er flerfunksjonelle innebærer at de har betydning på flere ulike nivå (polyfunksjonelle) og hver betydning begrenser framtidige mulige endringer. Ett annet eks. er når ord inngår i flere dimensjoner som i kryssord (vannrett-loddrett). En slik (fullstendig) flerfunksjonell løsning, er det vanskelig å rette på, uten å ødelegge andre sammenhenger. (Brukte kryssord som et kjent eks; selv om det finnes bedre-
oversetters anmerkning).

Bilde 4: Endring i ett ord kan påvirker gjerne flere
Det er rikelig bevis på at de fleste DNA-sekvenser er fler-funksjonelle, og dermed flersidig-begrenset (Trifonov, 1998). F.eks. kan de fleste menneskelige kodende-sekvenser leses i motsatte retninger, hvilket innebærer at begge DNA-halvdelene kopieres (Yelin et al, 2003). Noen sekvenser koder for ulike proteiner avhengig av hvor avlesingen starter. Noen sekvenser koder for ulike proteiner basert på alternativ mRNA-spleising. Noen sekvenser tjener simultant flere funksjoner (protein-koding og som intern oversettelses promotør). Noen sekvenser koder både for en protein kodende region og en protein-bindende region etc. Aritmetisk, logiske enheter (Alu) og opphav til replikasjon, kan bli funnet innen fuksjonelle promotører og innen eksoner m.m. Vi vet også at det er et helt annet nivå på organiseringen innen det epigenetiske nivå (Gibbs, 2003). Det synes også å være omfangsrike , sekvens-avhengige, tre-dimensjonal organisering innen kromosomer og innen hele kjernen. (Manuelidis, 1990; Gardiner, 1995; Flam, 1994) Trifonov (1989) har vist at muligens alle DNA-sekvenser i genomet krypterer multiple koder (opp til 12). I studiet av informasjonssystemer kan denne type av data-komprimering bare komme av høyeste nivå av informasjons-design, og resulterer i maksimal informasjons-tetthet. Disse høyere nivåer av genomets organisering/informasjons innhold, øker sterkt fokuset på flersidig-begrenset DNA. Å endre noe, synes potensielt å endre alt. Den flersidig-begrensede naturen ved DNA, tjener som sterkt bevis på at høyere genom ikke kan utvikles via mutasjon/seleksjon uten på et trivielt nivå.
8. Ikke-reduserbar kompleksitet
Problemet med ikke-reduserbar kompleksitet er beskrevet av M. Behe (1996). Han har illustrert konseptet med ikke-reduserbar kompleksitet i ulike systemer som har multiple komponenter, f.eks. en bakterieflagell som har 20-30 komponent-deler. Poenget i følge Behe er at hver komponent (del) ikke har noen verdi utenfor konteksten med hele den funksjonelle enheten. Ikke-reduserbare systemer må dermed komme sammen under ett, i stedet for å dannes ved en enhet (komponent) om gangen. Det molekylære maskineriet som ligger under protein-syntesen er fantastisk. Mer komplekse protein-molekyler har mange hundre komponent-deler. Men det underliggende gen har som produserer det, har tusener av komponent-deler. Alle disse delene samvirker, og definerer hverandre gjensidig. Hver nukleotide har bare mening i kontekst av alle de andre. Hver nukleotide er poly-funksjonell og samvirker med mange andre polyfunksjonelle nukleotider.
DNA-sekvensen definerer regionale 3-dimensjonale kromatin strukturer, lokale protein bindinger, koding for avlesning, utrulling/ sammentrekning, og definerer også en eller flere RNA-sekvenser. RNA-sekvensen definerer RNA-stabilitet, RNA-variabel spleising, RNA prosessering, RNA-transport, avskrivnings-effektivitet og protein-sekvenser.
Bilde 5: Aktivitet i cellen, -som er ikke-reduserbar
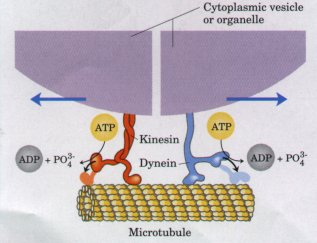 Vi skjønner ikke helheten i hvordan ett enkelt gen i høyere livsformer arbeider, sett i sammenheng med alt annet som skjer i cellen. Ett enkelt gen med alle sine samhandlinger, er ennå for kompleks for oss. Når vi betrakter den fulle kompleksiteten til ett gen, inkludert dets regulerende og arkitektoniske elementer, så har ett enkelt gen omkring 50.000 komponent deler. Ett enkelt gen er en mikroskopisk flekk, av ikke-reduserbar kompleksitet som utgjør en enkelt celle. Livet selv, er essensen av ikke-reduserbar kompleksitet, som er grunnen til at vi ikke kan begynne å tenke på å danne liv på egen hånd. Livet er lag på lag av ikke-reduserbar kompleksitet. Våre beste flytdiagram, er bare barnemat i forhold til virkelig biologisk kompleksitet. Det beste vi kan gjøre er å etterape naturen, for å kopiere dens genialitet.
Vi skjønner ikke helheten i hvordan ett enkelt gen i høyere livsformer arbeider, sett i sammenheng med alt annet som skjer i cellen. Ett enkelt gen med alle sine samhandlinger, er ennå for kompleks for oss. Når vi betrakter den fulle kompleksiteten til ett gen, inkludert dets regulerende og arkitektoniske elementer, så har ett enkelt gen omkring 50.000 komponent deler. Ett enkelt gen er en mikroskopisk flekk, av ikke-reduserbar kompleksitet som utgjør en enkelt celle. Livet selv, er essensen av ikke-reduserbar kompleksitet, som er grunnen til at vi ikke kan begynne å tenke på å danne liv på egen hånd. Livet er lag på lag av ikke-reduserbar kompleksitet. Våre beste flytdiagram, er bare barnemat i forhold til virkelig biologisk kompleksitet. Det beste vi kan gjøre er å etterape naturen, for å kopiere dens genialitet.
9. Nesten alle tjenlige mutasjoner må være ‘nesten nøytrale’
Som avdekket av Kimura (1997), gjør problemet med ‘nesten-nøytralitet’ at essensielt alle tjenlige mutasjoner faller innenfor ‘Ikke-seleksjons-sonen’ oppdaget av Kimura. Ingen slike mutasjoner kan det selekteres på. Vårt lenge etterlengtede nye gen, må visst ha noen få nukleotider som har betydelige effekter. F.eks. de som spesifiserer de aktive sidene på enzym. Men slike nukleotider kan bare ha viktige virkninger i konteksten til hele proteinet og hele gen-sekvensen. De individuelle nukleotidene i genet har bare en liten innvirkning på hele enheten, og mindre innflytelse på fitness ved hele individet. I kombinasjon med hverandre inneholder disse nukleotidene mesteparten av informasjonen som genet inneholder. Likevel er de individuelle nukleotidene ikke-selekterbare. Så hvordan kan de etableres og holde på plass under gen-konstruksjonen? Det som gjelder for den store massen av nukleotider, gjelder også for ‘elite-nukleotidene’. På grunn av ‘nesten-nøytral’ problemet når vi ikke engang til 1. stadium i å bygge vårt  ‘håpefulle gen’. Det blir ingen måte ut fra naturalistisk evolusjonsteori verken å ‘sette dem på plass’ eller å ‘holde dem der’. ‘Nær nøytral’ problemet er sterkt bevis for at hvert gen må være designet, og at det ikke finnes noen måte den kan bygges på nukleotide for nukleotide, via seleksjon.
‘håpefulle gen’. Det blir ingen måte ut fra naturalistisk evolusjonsteori verken å ‘sette dem på plass’ eller å ‘holde dem der’. ‘Nær nøytral’ problemet er sterkt bevis for at hvert gen må være designet, og at det ikke finnes noen måte den kan bygges på nukleotide for nukleotide, via seleksjon.
Bilde 6: Kimuras ikke-seleksjons sone
10. De dårlige mutasjonene -igjen
Vi har betraktet ulike argument for at progressive mutasjoner må være meget begrenset i sin rekkevidde/betydning. Det skyldes bl.a. det faktum at progressive seleksjoner blir opptrer i et antall av 1: 1-million i forhold til skadelige mutasjoner. Vi skal nå se litt mer på disse:
a)
Muller’s sperreverk –Som nevnt, har vi essensielt ikke historisk bevis for rekombinasjon innen det menneskelige genom, med dets store blokker (clustre) av DNA. Rekombinasjon synes primært å være mellom gener, ikke mellom nukleotider. Så mellom begrensede gen-sekvenser, er det essensielt ingen rekombinasjoner. Enhver slik blokk som ikke har rekombinasjon, er emne for ‘Muller’s sperreverk’ Det
innebærer at de gode og de dårlige ikke kan separeres. Siden de dårlige overgår de gode så totalt i antall, kan vi være sikre på at slike DNA-strekk av DNA må degenerere. Horden av dårlige mutasjoner, vil alltid dra de tjenlige med seg i dragsuget. Selv om vi i teorien skulle ha 99 gode mutasjoner, innen en region, så ville vi oppleve at mens vi ventet på én ny god mutasjon, så ville vi se at flere av de andre begynne å degenere. Tiden blir en fiende, da informasjon avtar med tiden. Muller’s sperreverk vil drepe ett nytt gen, lenge før det kan ta fasong.
 b) For mye seleksjons-kostnad- Vi har diskutert seleksjons-kostnader, f.eks. i forbindelse med Haldane’s dilemma-som kun betraktet tjenlige mutasjoner. Men vi har bare råd til å ‘betale for’ progressive mutasjoner, etter å ha betalt alle andre reproduksjons-kostnader, inklusive alle kostnader med eliminasjon av ødeleggende mutasjoner. Siden det er så mange ødeleggende mutasjoner, har vi ikke engang råd til å betale kostnadene med å eliminere dem. Det finnes en måte å omgå problemet, men det innebærer å låne ‘seleksjons-penger’ fra vår langvarige kamp mot skadelige mutasjoner. Selv om en på kort sikt kan få noen positive virkninger, blir effekten uvegerlig degenerasjon på lang sikt.
b) For mye seleksjons-kostnad- Vi har diskutert seleksjons-kostnader, f.eks. i forbindelse med Haldane’s dilemma-som kun betraktet tjenlige mutasjoner. Men vi har bare råd til å ‘betale for’ progressive mutasjoner, etter å ha betalt alle andre reproduksjons-kostnader, inklusive alle kostnader med eliminasjon av ødeleggende mutasjoner. Siden det er så mange ødeleggende mutasjoner, har vi ikke engang råd til å betale kostnadene med å eliminere dem. Det finnes en måte å omgå problemet, men det innebærer å låne ‘seleksjons-penger’ fra vår langvarige kamp mot skadelige mutasjoner. Selv om en på kort sikt kan få noen positive virkninger, blir effekten uvegerlig degenerasjon på lang sikt.
Bilde 7: Stadig degenerering Eks. på Muller sperreverk
c) Ikke-tilfeldige mutasjoner – Det viser seg faktisk at mutasjoner ikke er totalt tilfeldige. Så kan en undres om det vil hjelpe i å danne nye gener? La oss betrakte problemstillingen: Vi vet nå at noen nukleotide-posisjoner har mye større sannsynlighet for å mutere enn andre (hot-spots), og at noen nukleotider er favorisert i substitusjoner. Mutasjons hot-spots kan gi oss mutasjoner raskere i den lokasjonen, men mens vi venter på samsvarende mutasjoner andre steder (cold spots), så vil hot-spots mutere tilbake igjen. En må reselektere tjenlige mutasjoner innen hot-spots, mens vi venter på selv den første gode mutasjonen innen ‘cold-spots’. En større tendens til å mutere til f.eks. T i en bestemt lokasjon, vil være tjenlig om det er T vi ønsker. Men det vil sinke tjenlige mutasjoner om det en av de andre tre (C,A,G) som trengs. Gjennomsnittlig vil bias mot T-mutasjoner forsinke progressive mutasjoner i 75% av tilfellene. Dessverre er det en form for Ikke-tilfeldige mutasjoner som hindrer informasjons-bygging.
Bilde 8. Eks. på bakterie-flagell
 11. Tilleggskommentar
11. Tilleggskommentar
I boka 'The Edge of Evolution' (2007) bedømmer M. Behe massive empiriske data, knyttet til tre viktige medisinske mikroorganismer (AIDS-virus, malaria-viruset og E-coli bakterien). Disse mikroorganismene er kjent for å være meget muterbare og gjennomgå massive seleksjons-sykluser. De blir referert til som 'kraftfulle eksempler på evolusjonære systemer'. Behe viser at mens disse organismene raskt tilpasser seg nye eksterne omgivelser, så frambringer de ingen indre funksjonelle endringer. Selv innen disse 'ideelle evolusjonære systemene', så representerer type endring bare 'fine-tuning', ikke sanne nyskapninger. Selv om forskere har fulgt disse organismene gjennom et enormt antall reproduktive sykluser, mange flere enn det høyere organismer har gjennomlevd på jorda, så har alle observerte endringer bare vært midlertidige virkemidler. Behe viser klart at det primære aksiomet ikke kan skape ikke-reduserbar kompleksitet, selv på enkleste nivå.
Oppsummering:
Vi har altså sett at, selv om vi ignorerer ødeleggende mutasjoner, så kan ikke mutasjoner/seleksjon bygge opp ett eneste gen, innen tidsrammen for menneskets evolusjonære tidsskala. Når ødeleggende mutasjoner blir faset inn igjen, ser via at mutasjoner/seleksjon ikke noensinne kan danne ett enkelt gen. I forhold til det Primære aksiom som hevder at mutasjoner og naturlig seleksjon har dannet all nåværende biologisk informasjon, så er dette i praksis et formelt bevis mot funksjonaliteten i det Primære aksiomet.
8. Ikke-reduserbar kompleksitet
Problemet med ikke-reduserbar kompleksitet er beskrevet av M. Behe (1996). Han har illustrert konseptet med ikke-reduserbar kompleksitet i ulike systemer som har multiple komponenter, f.eks. en bakterieflagell som har 20-30 komponent-deler. Poenget i følge Behe er at hver komponent (del) ikke har noen verdi utenfor konteksten med hele den funksjonelle enheten. Ikke-reduserbare systemer må dermed komme sammen under ett, i stedet for å dannes ved en enhet (komponent) om gangen. Det molekylære maskineriet som ligger under protein-syntesen er fantastisk. Mer komplekse protein-molekyler har mange hundre komponent-deler. Men det underliggende gen har som produserer det, har tusener av komponent-deler. Alle disse delene samvirker, og definerer hverandre gjensidig. Hver nukleotide har bare mening i kontekst av alle de andre. Hver nukleotide er poly-funksjonell og samvirker med mange andre polyfunksjonelle nukleotider.
DNA-sekvensen definerer regionale 3-dimensjonale kromatin strukturer, lokale protein bindinger, koding for avlesning, utrulling/ sammentrekning, og definerer også en eller flere RNA-sekvenser. RNA-sekvensen definerer RNA-stabilitet, RNA-variabel spleising, RNA prosessering, RNA-transport, avskrivnings-effektivitet og protein-sekvenser.
Bilde 5: Aktivitet i cellen, -som er ikke-reduserbar
Vi skjønner ikke helheten i hvordan ett enkelt gen i høyere livsformer arbeider, sett i sammenheng med alt annet som skjer i cellen. Ett enkelt gen med alle sine samhandlinger, er ennå for kompleks for oss. Når vi betrakter den fulle kompleksiteten til ett gen, inkludert dets regulerende og arkitektoniske elementer, så har ett enkelt gen omkring 50.000 komponent deler. Ett enkelt gen er en mikroskopisk flekk, av ikke-reduserbar kompleksitet som utgjør en enkelt celle. Livet selv, er essensen av ikke-reduserbar kompleksitet, som er grunnen til at vi ikke kan begynne å tenke på å danne liv på egen hånd. Livet er lag på lag av ikke-reduserbar kompleksitet. Våre beste flytdiagram, er bare barnemat i forhold til virkelig biologisk kompleksitet. Det beste vi kan gjøre er å etterape naturen, for å kopiere dens genialitet.
9. Nesten alle tjenlige mutasjoner må være ‘nesten nøytrale’
Som avdekket av Kimura (1997), gjør problemet med ‘nesten-nøytralitet’ at essensielt alle tjenlige mutasjoner faller innenfor ‘Ikke-seleksjons-sonen’ oppdaget av Kimura. Ingen slike mutasjoner kan det selekteres på. Vårt lenge etterlengtede nye gen, må visst ha noen få nukleotider som har betydelige effekter. F.eks. de som spesifiserer de aktive sidene på enzym. Men slike nukleotider kan bare ha viktige virkninger i konteksten til hele proteinet og hele gen-sekvensen. De individuelle nukleotidene i genet har bare en liten innvirkning på hele enheten, og mindre innflytelse på fitness ved hele individet. I kombinasjon med hverandre inneholder disse nukleotidene mesteparten av informasjonen som genet inneholder. Likevel er de individuelle nukleotidene ikke-selekterbare. Så hvordan kan de etableres og holde på plass under gen-konstruksjonen? Det som gjelder for den store massen av nukleotider, gjelder også for ‘elite-nukleotidene’. På grunn av ‘nesten-nøytral’ problemet når vi ikke engang til 1. stadium i å bygge vårt ‘håpefulle gen’. Det blir ingen måte ut fra naturalistisk evolusjonsteori verken å ‘sette dem på plass’ eller å ‘holde dem der’. ‘Nær nøytral’ problemet er sterkt bevis for at hvert gen må være designet, og at det ikke finnes noen måte den kan bygges på nukleotide for nukleotide, via seleksjon.
Bilde 6: Kimuras ikke-seleksjons sone
10. De dårlige mutasjonene -igjen
Vi har betraktet ulike argument for at progressive mutasjoner må være meget begrenset i sin rekkevidde/betydning. Det skyldes bl.a. det faktum at progressive seleksjoner blir opptrer i et antall av 1: 1-million i forhold til skadelige mutasjoner. Vi skal nå se litt mer på disse:
a)
Muller’s sperreverk –Som nevnt, har vi essensielt ikke historisk bevis for rekombinasjon innen det menneskelige genom, med dets store blokker (clustre) av DNA. Rekombinasjon synes primært å være mellom gener, ikke mellom nukleotider. Så mellom begrensede gen-sekvenser, er det essensielt ingen rekombinasjoner. Enhver slik blokk som ikke har rekombinasjon, er emne for ‘Muller’s sperreverk’ Det
innebærer at de gode og de dårlige ikke kan separeres. Siden de dårlige overgår de gode så totalt i antall, kan vi være sikre på at slike DNA-strekk av DNA må degenerere. Horden av dårlige mutasjoner, vil alltid dra de tjenlige med seg i dragsuget. Selv om vi i teorien skulle ha 99 gode mutasjoner, innen en region, så ville vi oppleve at mens vi ventet på én ny god mutasjon, så ville vi se at flere av de andre begynne å degenere. Tiden blir en fiende, da informasjon avtar med tiden. Muller’s sperreverk vil drepe ett nytt gen, lenge før det kan ta fasong.
b) For mye seleksjons-kostnad- Vi har diskutert seleksjons-kostnader, f.eks. i forbindelse med Haldane’s dilemma-som kun betraktet tjenlige mutasjoner. Men vi har bare råd til å ‘betale for’ progressive mutasjoner, etter å ha betalt alle andre reproduksjons-kostnader, inklusive alle kostnader med eliminasjon av ødeleggende mutasjoner. Siden det er så mange ødeleggende mutasjoner, har vi ikke engang råd til å betale kostnadene med å eliminere dem. Det finnes en måte å omgå problemet, men det innebærer å låne ‘seleksjons-penger’ fra vår langvarige kamp mot skadelige mutasjoner. Selv om en på kort sikt kan få noen positive virkninger, blir effekten uvegerlig degenerasjon på lang sikt.